|
|
摘要:AI+农业:多模态地理空间的机器学习模型、漂亮的 GitHub 命令行面板、多种编程语言代码生成预训练模型、Python字符串快速模糊匹配库、将SQL表的可靠性和简单性带入大数据、Toy Model 的叠加、用数学和Python入门机器学习核方法 · 电子书、Kaggle比赛第1名解决方案 · 预测写作中的有效论点、前沿论文…

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子 ⚡ xxG 夺冠?人工智能预测英雄联盟S12冠军
https://weibo.com/tv/show/1034:4826223403270223
微博 @图灵的猫 用AI预测了2022年英雄联盟S12的总冠军——RNG。有趣的是,将『是否在比赛日7天内感染新冠』加入到选手特征之后,胜率有了明显变化,冠军预测结果变为 JDG!
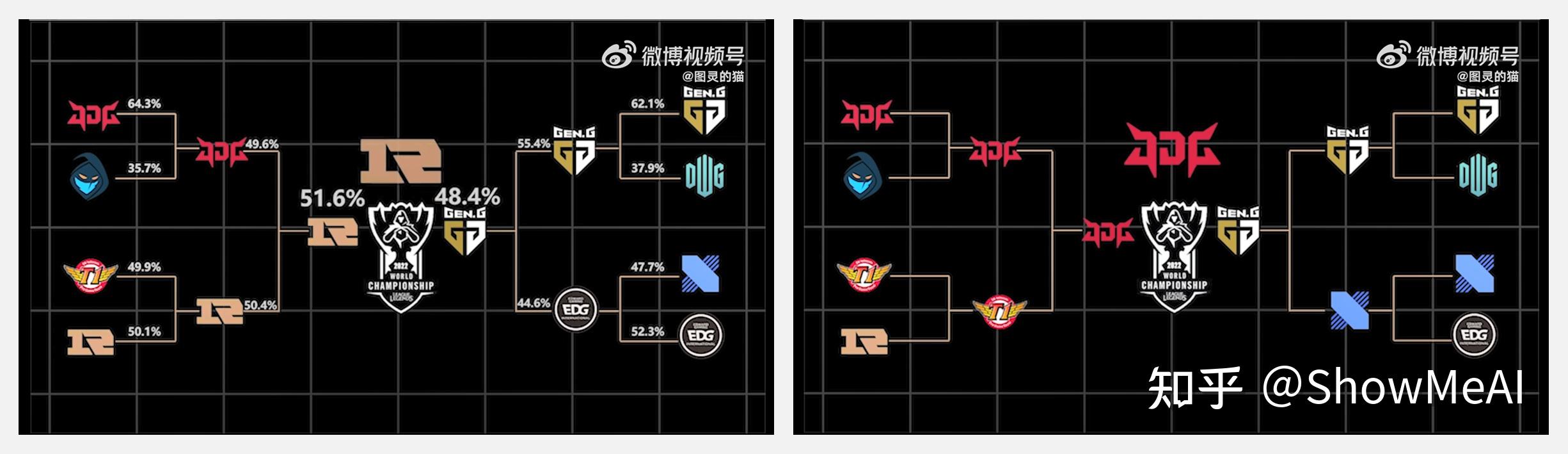
博主以单场比赛作为数据的基本维度,把过去每场比赛的胜率作为预测Label。模型用到以下几类特征:队伍特征(历史平均胜率、历史夺冠次数等),上下文特征(游戏版本号、BP阵容等),选手特征(年龄、赛季平均胜率等)。参考论文对原始数据进行处理后,输入构建的机器学习模型,得到预测结果。
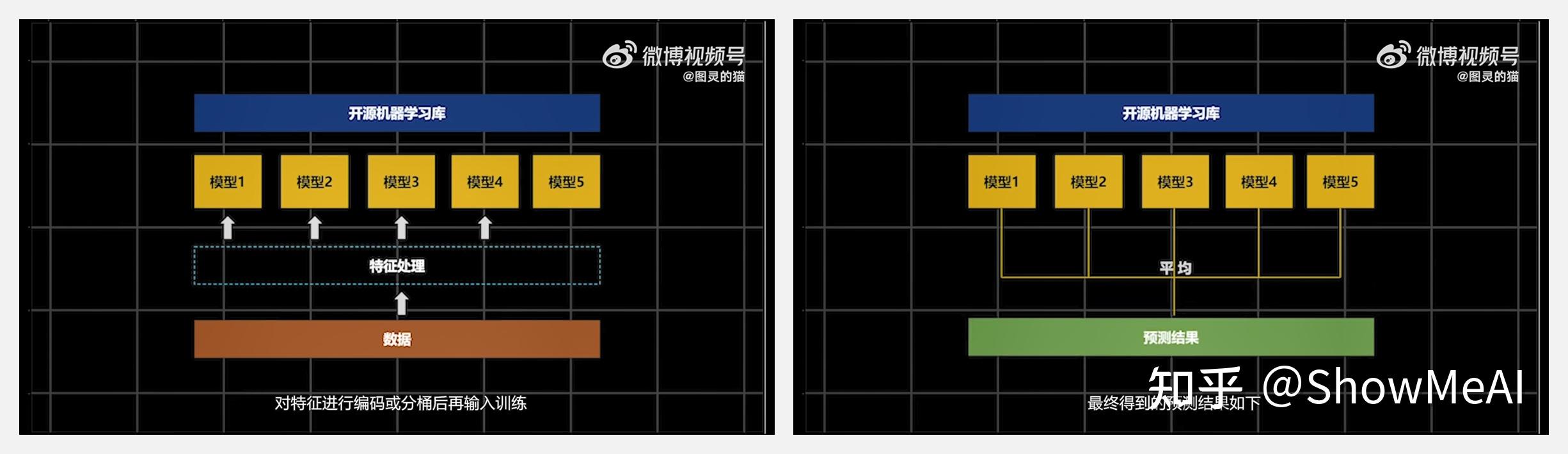
不过,博主也表示,本次预测缺乏很多细节数据,置信度并不高,只能算是对浅层世界的模拟。哪怕根据比赛实时数据进行预测,胜率也会有极大波动和反转——这种AI无法理解和预测的随机性,来自于每个队员对胜利的执着,这也正是电子竞技的魅力所在。
⚡ 『FarmVibes.AI』多模态地理空间的机器学习模型
https://github.com/microsoft/farmvibes-ai
FarmVibes.AI 是微软开放的多模态地理空间机器学习模型,可用于农业和可持续发展。这个模型可以使用融合了多个地理空间和时空数据集来建立模型,获得在孤立使用这些数据集时难以获得的洞察力——估计碳足迹、了解增长率等。
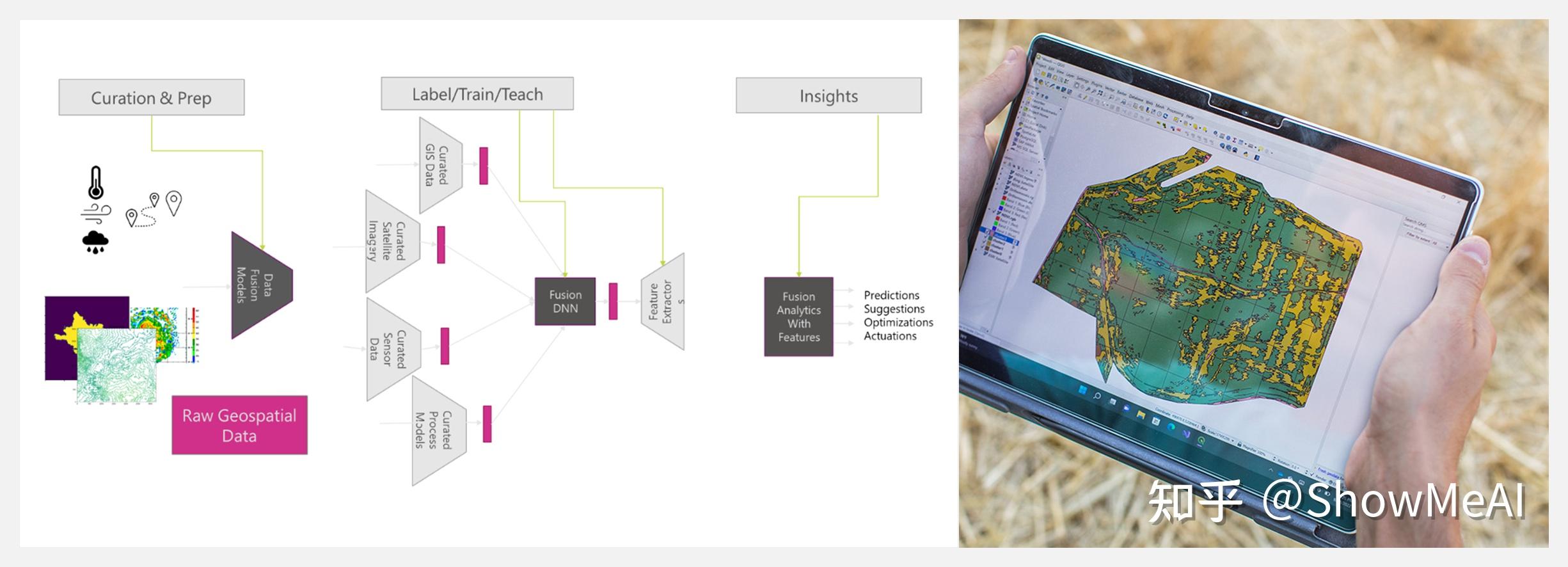
例如,FarmVibes.AI 可以将卫星图像(RGB、SAR、多光谱)、无人机图像、气象数据等融合在一起进行研究,使用地面传感器以及无人机和卫星图像来创建选定土地上的养分和水分分布图,为农民提供有关肥料和种子应该放置的位置的信息,从而减少过度施肥和浪费。
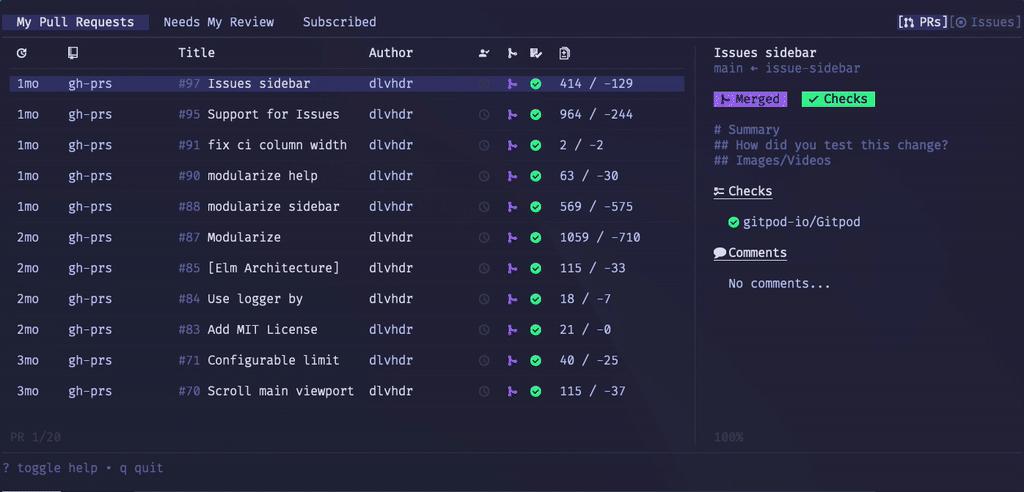
⚡ 『gh-dash』漂亮的 GitHub 命令行面板
https://github.com/dlvhdr/gh-dash
gh-dash是一个漂亮的GitHub命令行面板,它会在终端显示一个仪表板,上面包括你关心的pull requests和issues。
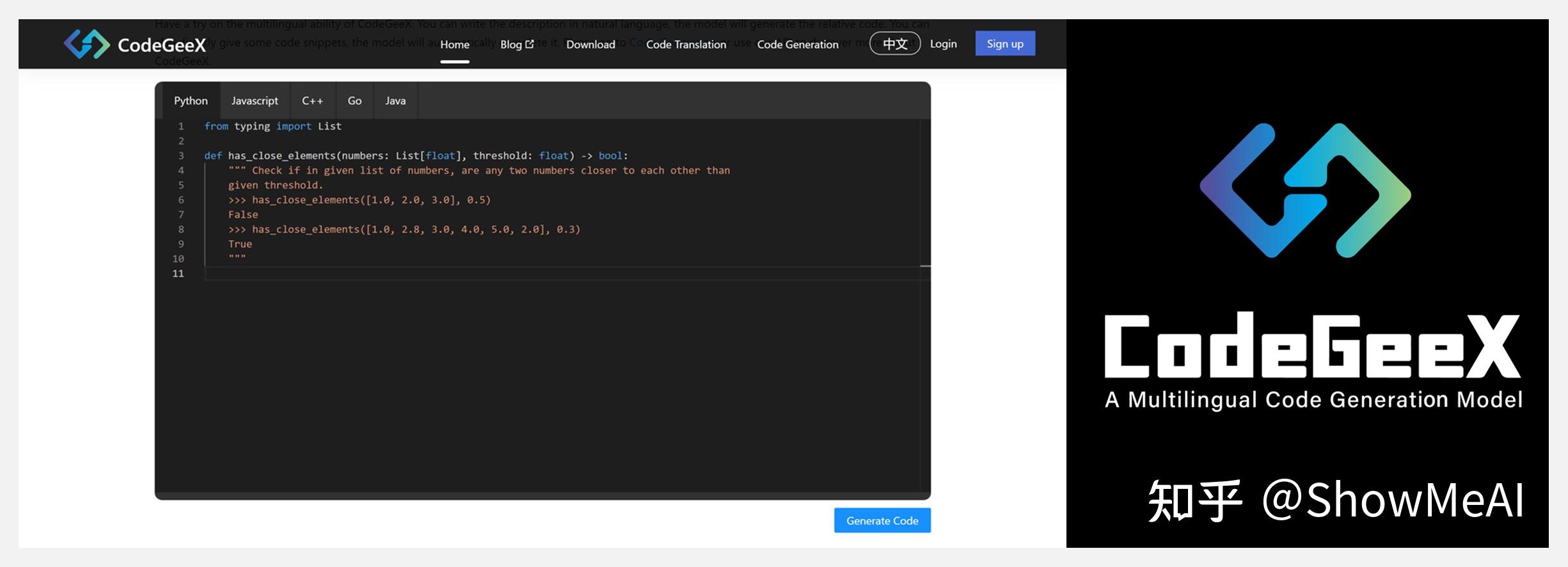
⚡ 『CodeGeeX』具有 130 亿参数的多编程语言代码生成预训练模型
https://github.com/THUDM/CodeGeeX
https://models.aminer.cn/codegeex/
CodeGeeX 是一个拥有 130 亿个参数的大规模多语言代码生成模型,在20多种编程语言的大型代码语料库上进行预训练获得。
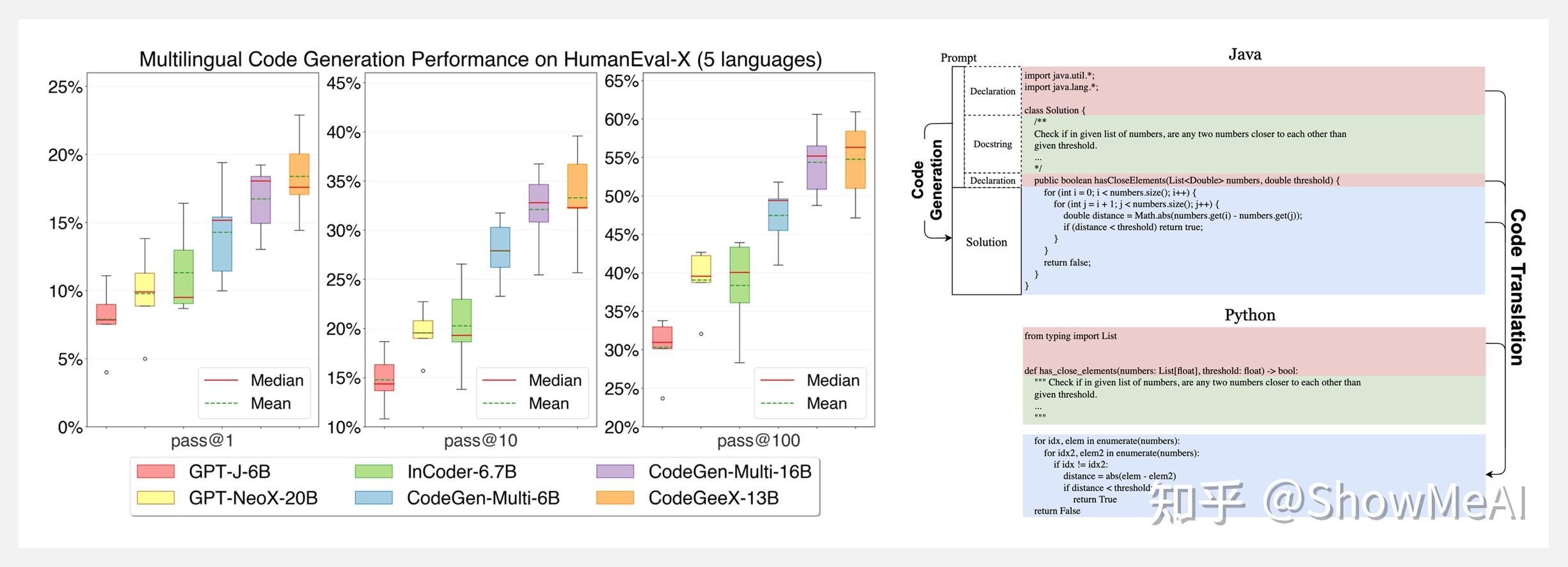
CodeGeeX 具有多种特性:多语言代码生成、跨语言的代码翻译、可定制的编程助手、开源和跨平台。其中,CodeGeeX 可以生成 Python、C++、Java、JavaScript、Go等主流编程语言的可执行程序且性能良好,并且支持不同语言间的代码片段的高精度翻译。非常酷!
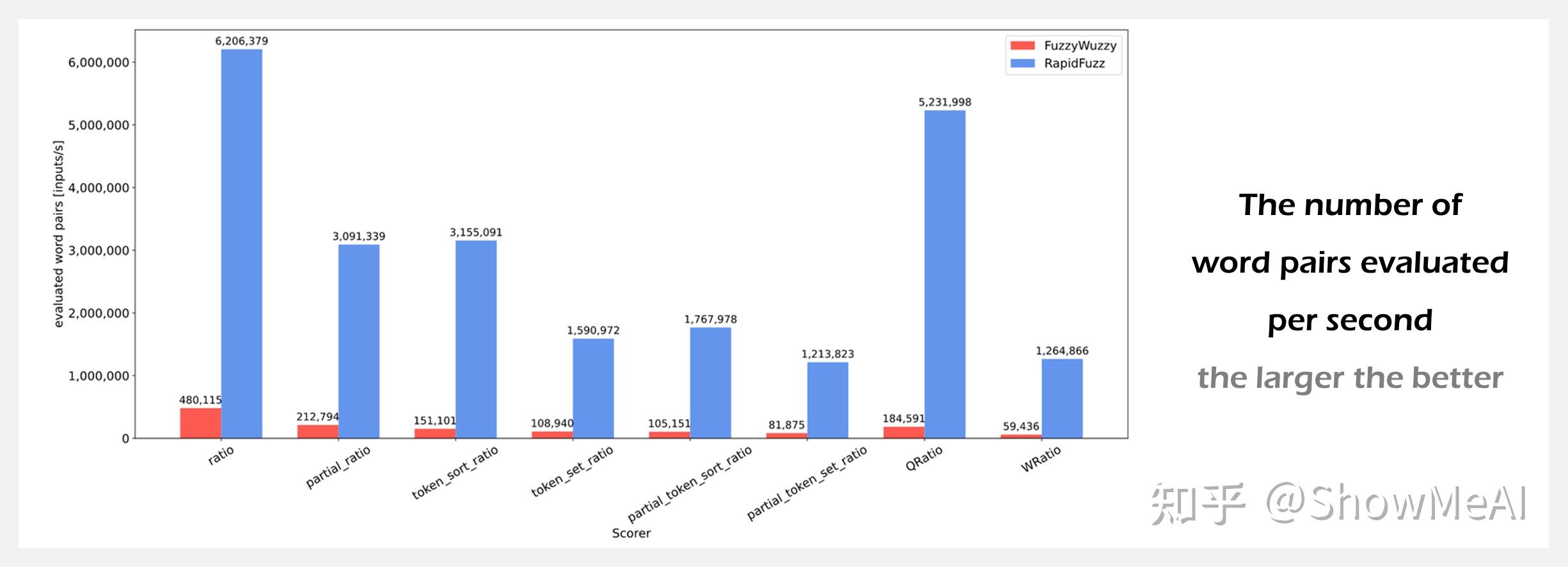
⚡ 『RapidFuzz』Python字符串快速模糊匹配库
https://github.com/maxbachmann/rapidfuzz
https://maxbachmann.github.io/RapidFuzz/
RapidFuzz 是一个用于 Python 和 C++ 的快速字符串匹配库,它采用了 FuzzyWuzzy 的字符串相似度计算方法。它提供了许多像 hamming 或 jaro_winkler 这样的字符串指标,这些指标是 FuzzyWuzzy 所不具备的。
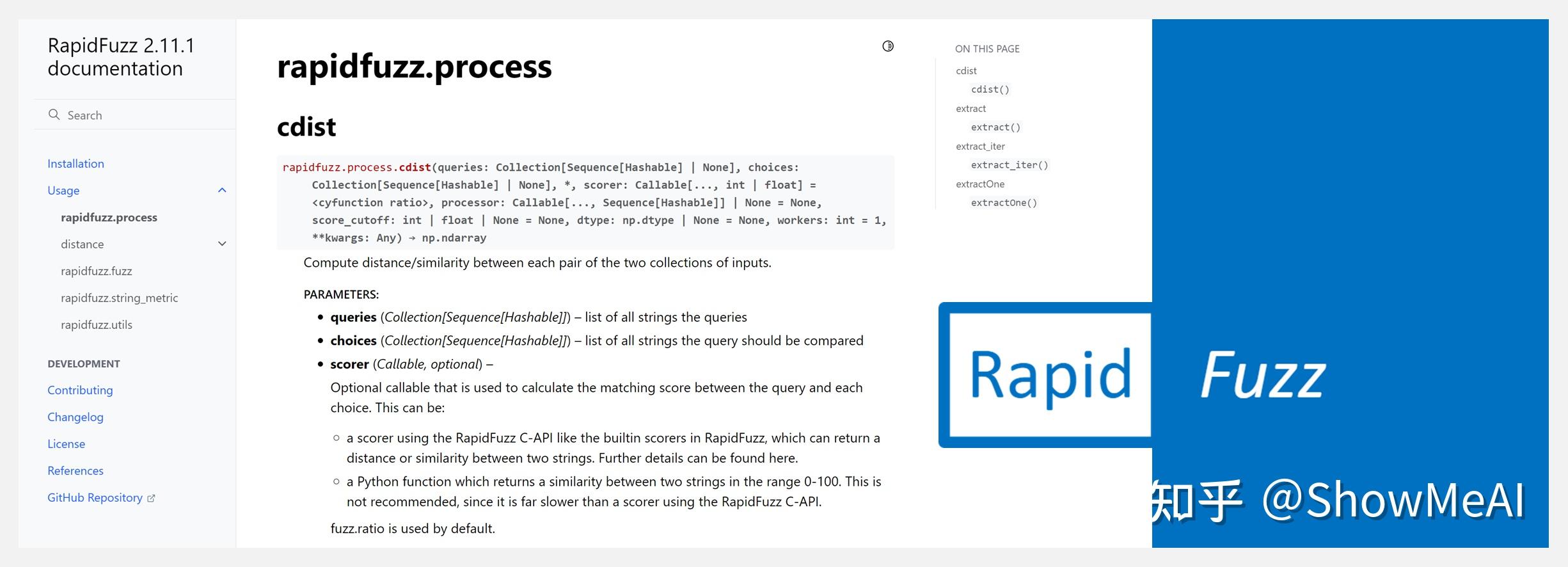
它主要是用C++编写的,并且在此基础上进行了大量的算法改进,以使字符串匹配更快,同时仍然提供相同的结果。它修复了partial_ratio实现中的多个bug。
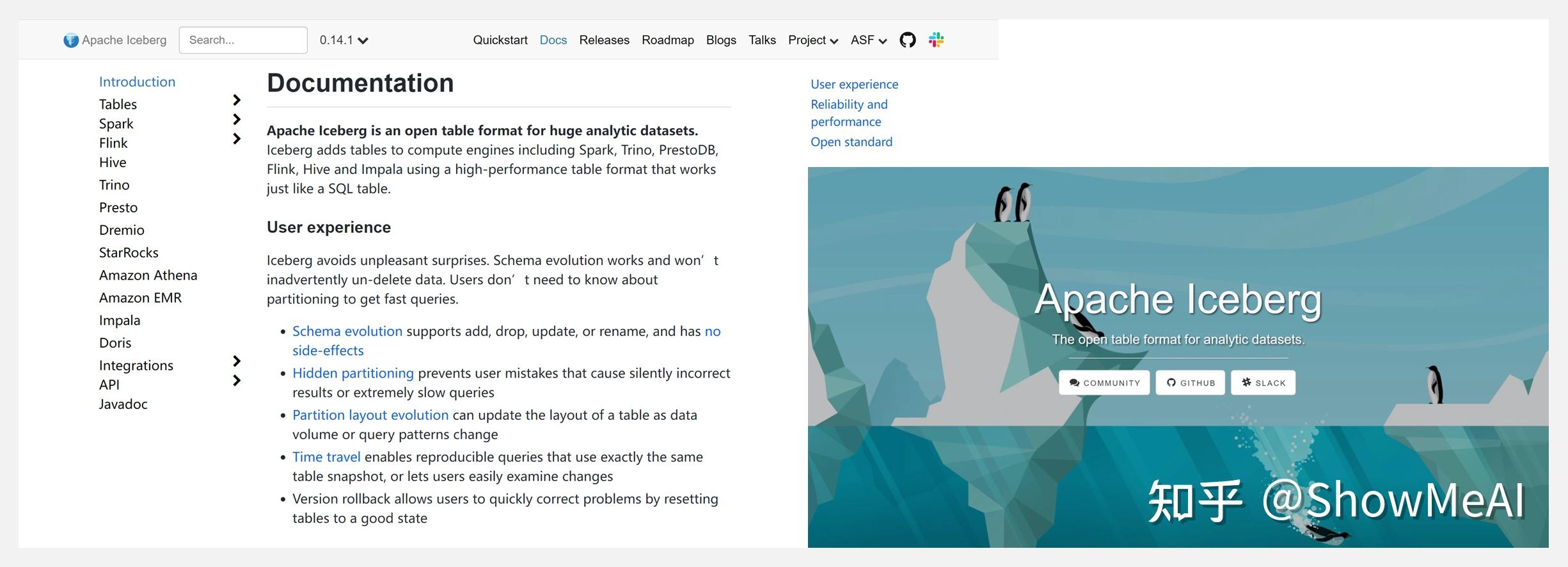
⚡ 『iceberg』将SQL表的可靠性和简单性带入大数据
https://github.com/apache/iceberg
https://iceberg.apache.org/
Iceberg 是一种用于大型分析表的高性能格式。 Iceberg 为大数据带来了 SQL 表的可靠性和简单性,同时让 Spark、Trino、Flink、Presto、Hive 和 Impala 等引擎能够同时安全地使用相同的表。
⚡ 『Toy Models of Superposition』Toy Model 的叠加:使用小型 ReLU 网络研究模型如何表示比自身维度更多的特征
https://transformer-circuits.pub/2022/toy_model/index.html
人工神经网络的单个神经元,与可清晰解释的输入特征,能够相互对应吗?例如,在理想的 ImageNet 分类器中,每个神经元仅在特定视觉特征(例如红色、左向曲线或狗的鼻子)下才会被触发。但是根据经验,这种神经元清晰地映射到特征的情况,并不经常出现。
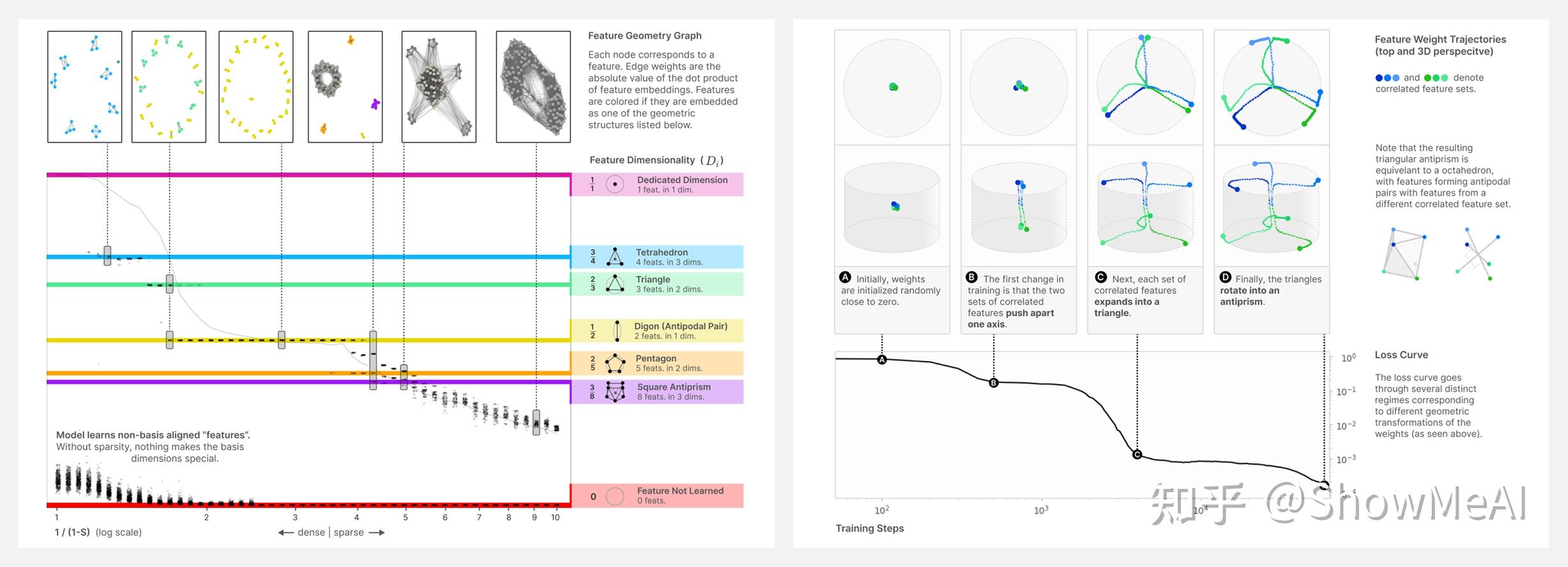
在本文中,我们使用Toy Model(在具有稀疏输入特征的合成数据上训练的小型 ReLU 网络)来研究模型如何以及何时表示比它们具有的维度更多的特征(本文称这种现象为叠加)。使用 Toy Model 的研究可以证明以下关键结论,但仍不清楚如何推广到真实网络:
- 叠加是一种真实的、可观察到的现象
- 单语义和多语义神经元都可以形成
- 至少可以叠加执行某些类型的计算
- 特征是否以叠加方式存储由相变决定
- 叠加将特征组织成几何结构,例如正方体、三角形、五边形和四面体
⚡ 『Kernel Methods for Machine Learning with Math and Python』用数学和Python入门机器学习核方法 · 电子书
https://bayesnet.org/books/
PDF: [100 Exercises for Building Logic](https://bibis.ir/science-books/programming/python/2022/Kernel Methods for Machine Learning with Math and Python 100 Exercises for Building Logic by Joe Suzuki_bibis.ir.pdf)
『Kernel (核)』的理解与使用,一直是学习者和机器学习研究人员的知识难点。作者整理推荐了一条最短的学习路径:从数学泛函分析开始(也就是本书的第2章)!这本书会给你一个坚实的基础,确保你能够流畅地阅读以前似乎很难理解的论文,并从更高的层次看到整个『核范式 (kernel paradigm)』。
本书选择了100个练习题并附上了代码和答案,读者可以通过阅读本书来解出所有习题,进而获得机器学习各主题的本质,并顺利跟上新技术的发展变化。本书包含以下章节:
- Positive Definite Kernels(正定核)
- Hilbert Spaces(希尔伯特空间)
- Reproducing Kernel Hilbert Space(再现核希尔伯特空间)
- Kernel Computations(核计算)
- The MMD and HSIC(MMD和HSIC)
- Gaussian Processes and Functional Data Analyses(高斯过程和功能数据分析)

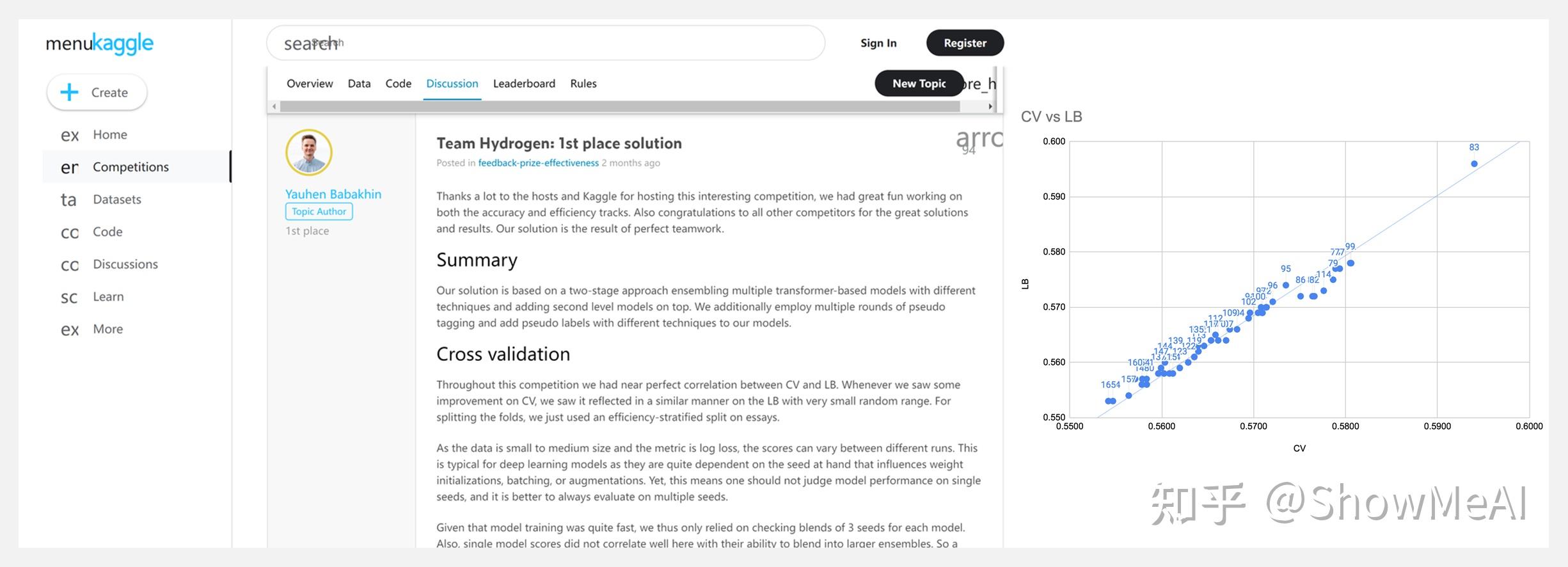
⚡ 『Feedback Prize - Predicting Effective Arguments』Kaggle比赛第1名解决方案 · 预测写作中的有效论点
https://github.com/ybabakhin/kaggle-feedback-effectiveness-1st-place-solution
https://www.kaggle.com/competitions/feedback-prize-effectiveness/discussion/347536
比赛使用美国 6 年级- 12年级的数据,通过建模将学生作文中的论点进行分类:effective/有效、充分/adequate、无效/ineffective。比赛模型将为学生的议论文写作提供反馈,帮助学生更好地完成作业,并成为更娴熟地写作者。

Repo分享了排名第1的解决方案:基于一种两阶段方法,使用不同的技术集成了多个基于transformer的模型,并在顶部添加了二级模型。还使用了多轮伪标记,并为模型添加了具有不同技术的伪标签。更多解决方案的细节见第二个链接。

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。 科研进展
- 2022.09.25 『文本转图像』 Personalizing Text-to-Image Generation via Aesthetic Gradients
- 2022.10.13 『领域泛化』Unified Vision and Language Prompt Learning
- 2022.10.06 『化学物理』 Equivariant Shape-Conditioned Generation of 3D Molecules for Ligand-Based Drug Design
⚡ 论文:Personalizing Text-to-Image Generation via Aesthetic Gradients
论文时间:25 Sep 2022
领域任务:Text to image generation, Text-to-Image Generation,文本转图像
论文地址:https://arxiv.org/abs/2209.12330
代码实现:https://github.com/vicgalle/stable-diffusion-aesthetic-gradients
论文作者:Victor Gallego
论文简介:This work proposes aesthetic gradients, a method to personalize a CLIP-conditioned diffusion model by guiding the generative process towards custom aesthetics defined by the user from a set of images./这项工作提出了审美梯度,这是一种通过引导生成过程走向用户从一组图像中定义的自定义美学来个性化CLIP条件的扩散模型的方法。
论文摘要:这项工作提出了审美梯度,这是一种通过引导生成过程走向用户从一组图像中定义的自定义美学来个性化CLIP条件的扩散模型的方法。该方法通过定性和定量实验进行验证,使用最近的稳定扩散模型和几个审美过滤的数据集。代码发布在https://github.com/vicgalle/stable-diffusion-aesthetic-gradients

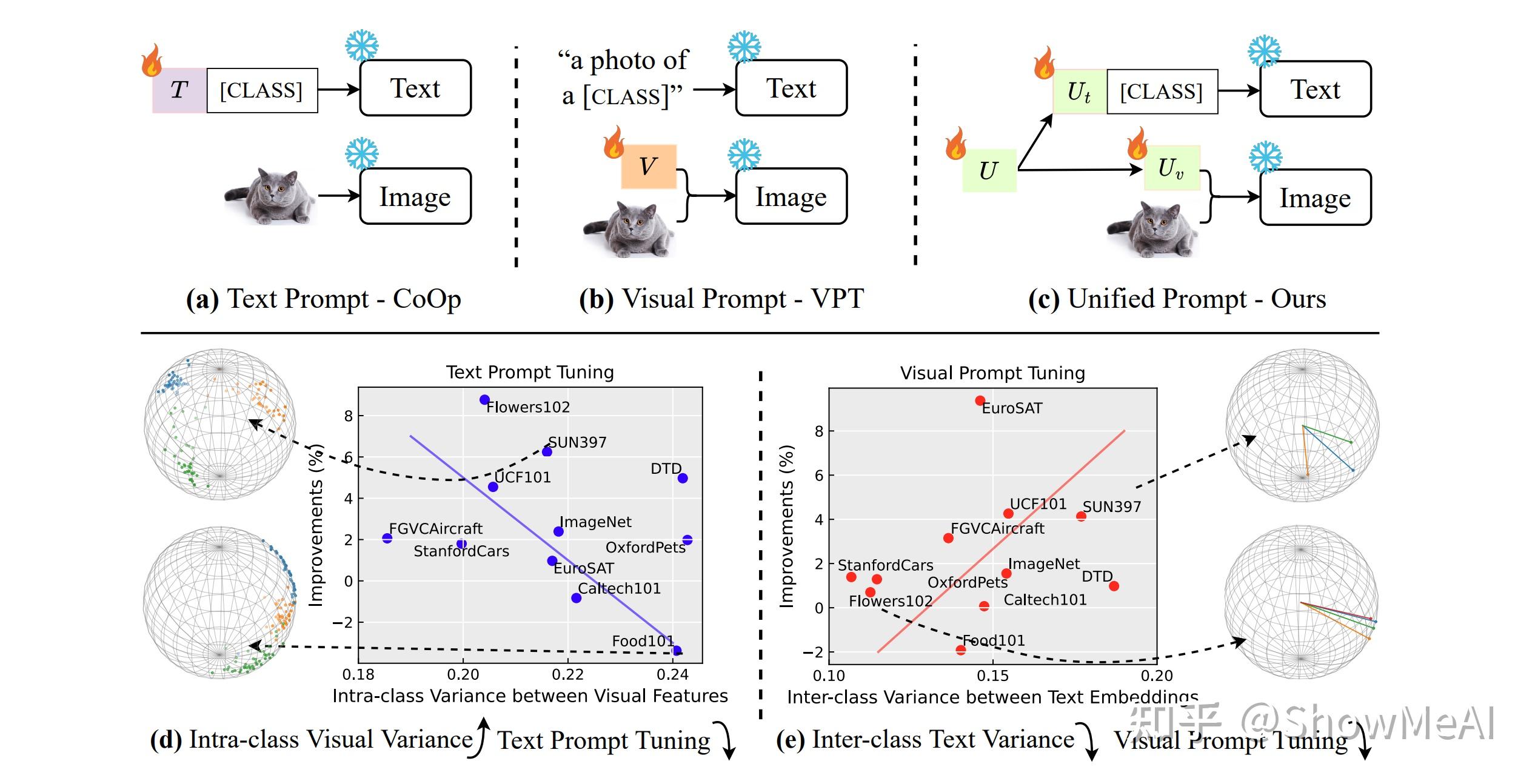
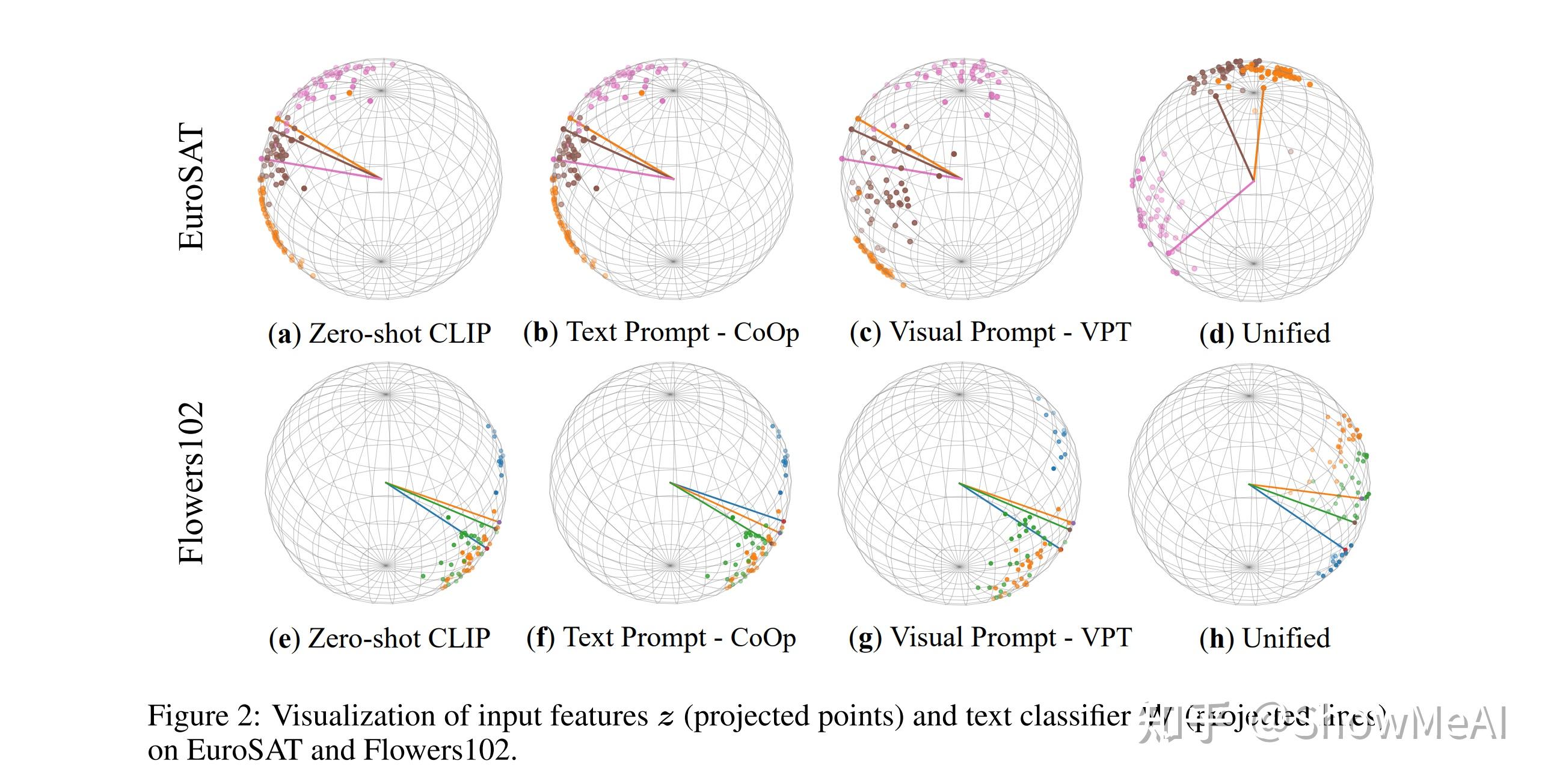
⚡ 论文:Unified Vision and Language Prompt Learning
论文时间:13 Oct 2022
领域任务:Domain Generalization, Few-Shot Learning, 领域泛化,Few-Shot 学习
论文地址:https://arxiv.org/abs/2210.07225
代码实现:https://github.com/yuhangzang/upt
论文作者:Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, Chen Change Loy
论文简介:Prompt tuning, a parameter- and data-efficient transfer learning paradigm that tunes only a small number of parameters in a model's input space, has become a trend in the vision community since the emergence of large vision-language models like CLIP./自从CLIP等大型视觉语言模型出现后,提示调谐,一种参数和数据高效的转移学习范式,只调整模型输入空间中的少量参数,已经成为视觉界的一种趋势。
论文摘要:自从CLIP等大型视觉语言模型出现后,提示调谐,一种参数和数据高效的转移学习范式,只调整模型输入空间中的少量参数,已成为视觉界的一种趋势。我们对两种有代表性的提示调谐方法,即文本提示调谐和视觉提示调谐进行了系统研究。一个主要的发现是,没有一种单模态的提示调谐方法表现得始终如一:文本提示调谐在具有高类内视觉变异的数据上失败,而视觉提示调谐不能处理低类间变异。为了结合两者的优点,我们提出了一个简单的方法,称为统一提示调谐(UPT),它基本上是学习一个微小的神经网络来共同优化不同模态的提示信息。在超过11个视觉数据集上的广泛实验表明,UPT在少许学习基准以及领域概括基准上比单模态的对应方法取得了更好的权衡。代码和模型将被发布以促进未来的研究。
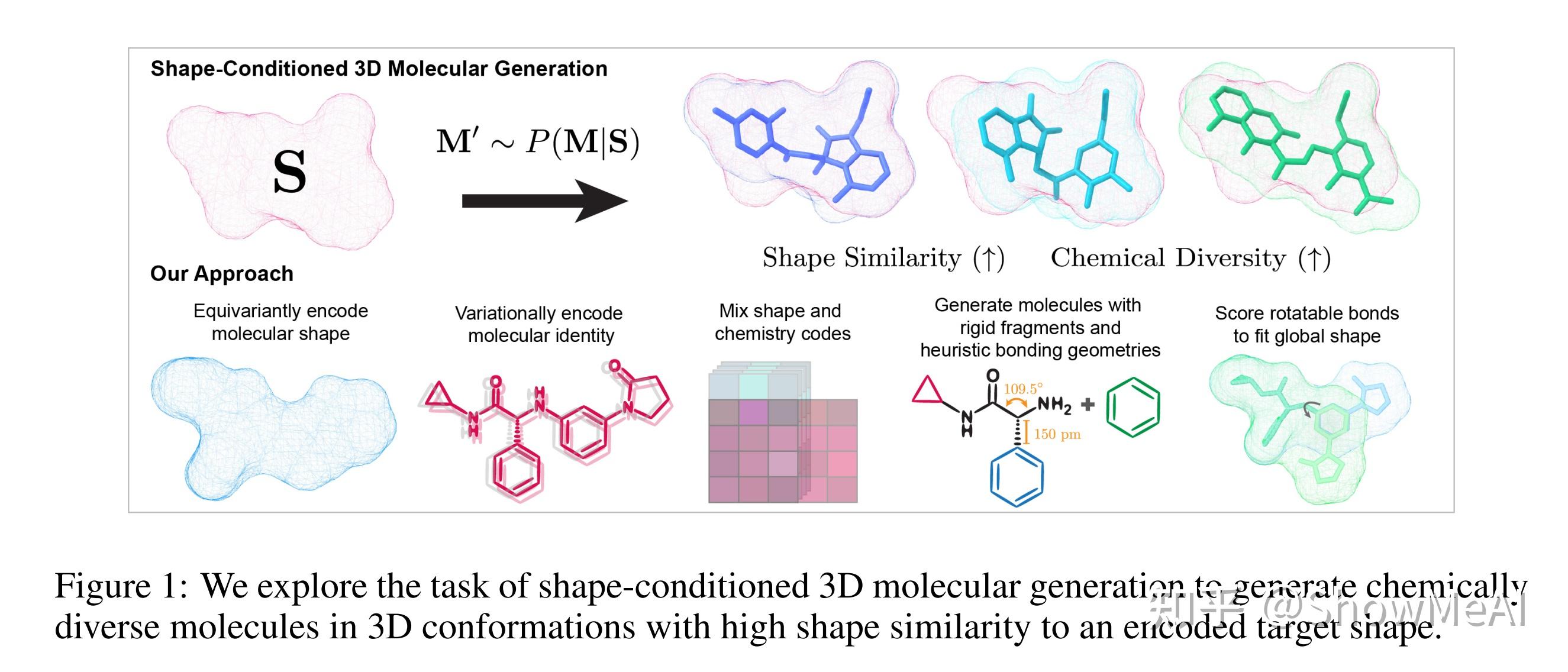
⚡ 论文:Equivariant Shape-Conditioned Generation of 3D Molecules for Ligand-Based Drug Design
论文时间:6 Oct 2022
领域任务:Chemical Physics, Machine Learning, Biomolecules, 化学物理、机器学习、生物分子
论文地址:https://arxiv.org/abs/2210.04893
代码实现:https://github.com/keiradams/squid
论文作者:Keir Adams, Connor W. Coley
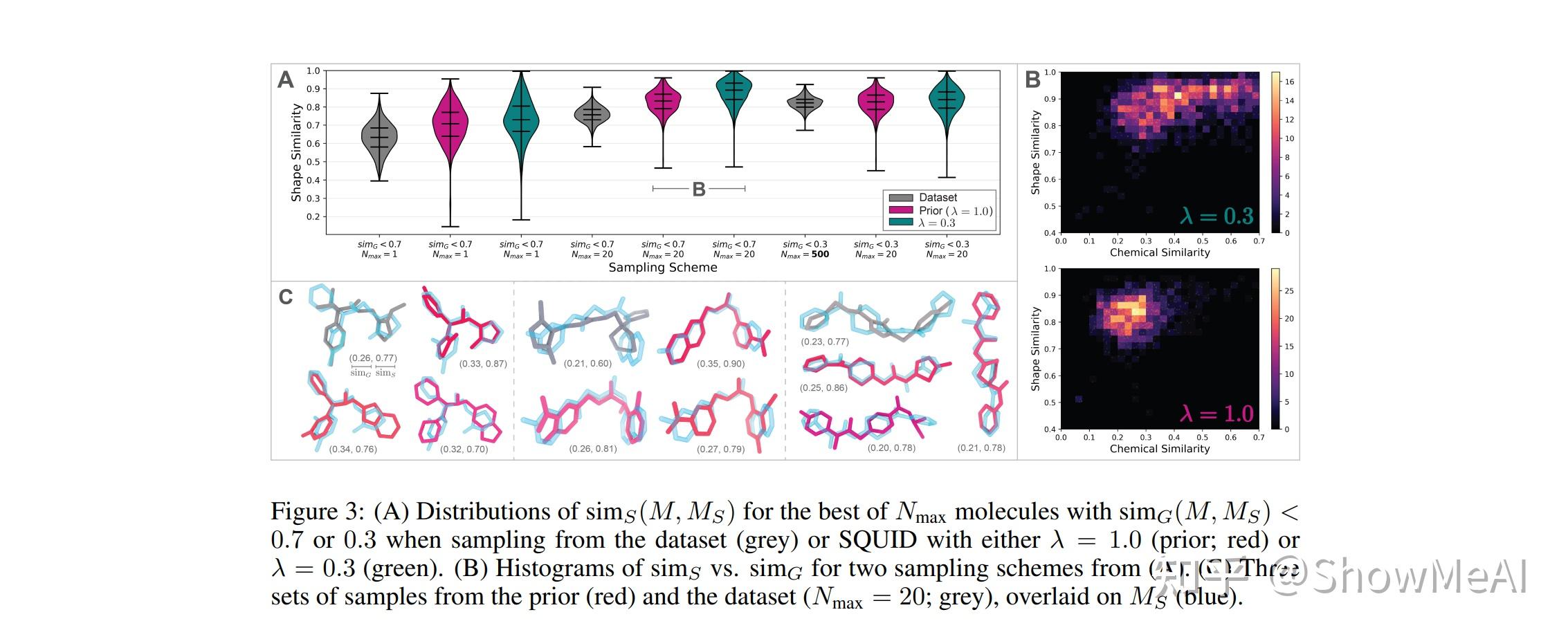
论文简介:Shape-based virtual screening is widely employed in ligand-based drug design to search chemical libraries for molecules with similar 3D shapes yet novel 2D chemical structures compared to known ligands./基于形状的虚拟筛选在基于配体的药物设计中被广泛采用,以搜索化学库中与已知配体具有相似的三维形状但具有新颖的二维化学结构的分子。
论文摘要:基于形状的虚拟筛选在基于配体的药物设计中被广泛采用,以搜索化学库,寻找与已知配体相比具有相似的三维形状和新颖的二维化学结构的分子。三维深度生成模型有可能使这种以形状为条件的三维化学空间的探索自动化;然而,现有的模型都不能可靠地生成有效的类似药物的分子,其构象采用特定的形状,如已知的结合姿势。我们引入了一个新的多模态三维生成模型,通过等价编码分子形状和变异编码化学特性来实现形状条件的三维分子设计。我们通过使用基于自回归片段的生成与启发式键合几何,确保生成分子的局部几何和化学有效性,使模型能够优先考虑可旋转键的评分,使不断增长的构象结构与目标形状最匹配。我们在与药物设计相关的任务中评估了我们的三维生成模型,包括化学多样性分子结构的形状条件生成和形状约束的分子特性优化,证明了它比列举库的虚拟筛选更有用。

ShowMeAI 致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击专栏 ,查看历史消息。公众号(ShowMeAI研究中心)回复关键字 日报 ,可以获取资源包(资料整理汇总与AI电子月刊)。 |
|



 发表于 2023-2-10 16:18:38
发表于 2023-2-10 16:18:38